Нет, но мне важна скорость однократных моделинговых операций Например, крутанул количество сегментов в цилиндре в 3д максе и как быстро оно их перестроит в сцене Все эти тесты на рендеринг, архивирование и прочее это полная чухня Настоящий тест это построение сцены руками в максе, солидворксе и т д))) Сколько времени ты потратишь на ожидание каждой операции То есть не процесс рисования, которым занимается видяха, а процесс создания таблиц координат и векторов Сразу вопрос, как это вообще оптимизируется в мультиядре И вообще возможно ли это применимо к разным операциям? Если например это цилиндр, то это разбивается на N cores групп сегментов и таким образом 8 ядер строят таблицу координат цилиндра в 8 раз быстрее И так далее А если это просто лофт из круга или куб в один сегмент? Каким макаром параллелить поток? Это вопрос не к себе, а к dassault systemes, autodesk Я думаю что в общей оценке ядро 3.5ГГц проиграет ядру 4.5, потому что далеко не все векторные операции параллелятся ядрами Кватернионы, массивы, nurms Кстати, векторные операции зашиты внутри всяких SSE Там целый пак интересных функций Кодить такое голым кодом на сях это тупо Надо подключать либы для работы с расширениями АЛУ
Комментарии: 11
Sergey
Это сингл кор?
Anonim
Мультикор
Sergey
Или новая версия какаято с другими попугаями? А какой бенч?
Anonim
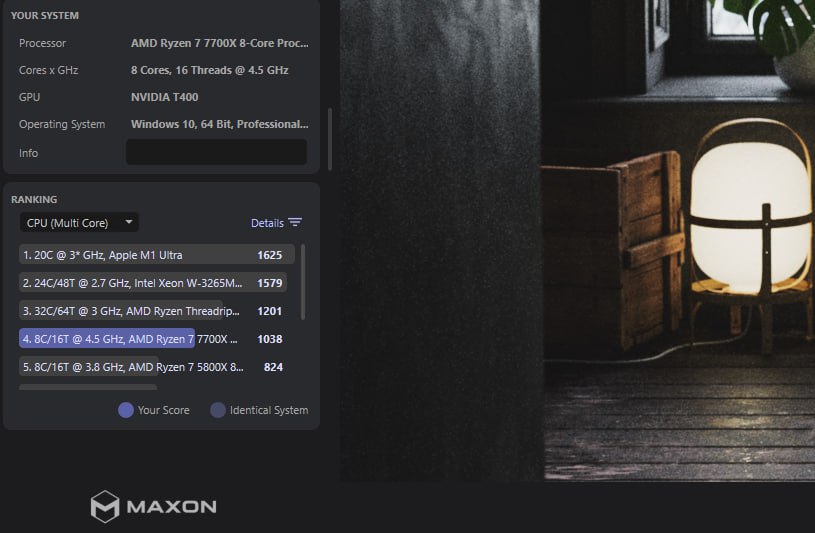
На тесте рендерится сцена, но не через видяху, а только процессором! Дефолтный
Sergey
2024 У меня последний замер в r23 Там попугаи в десятках тысяч для мультикор
Karboflex
При правильном сопле 1400 бывает) Ты в синебенче чтолибуш рендерить
Anonim
Нет, но мне важна скорость однократных моделинговых операций Например, крутанул количество сегментов в цилиндре в 3д максе и как быстро оно их перестроит в сцене Все эти тесты на рендеринг, архивирование и прочее это полная чухня Настоящий тест это построение сцены руками в максе, солидворксе и т д))) Сколько времени ты потратишь на ожидание каждой операции То есть не процесс рисования, которым занимается видяха, а процесс создания таблиц координат и векторов Сразу вопрос, как это вообще оптимизируется в мультиядре И вообще возможно ли это применимо к разным операциям? Если например это цилиндр, то это разбивается на N cores групп сегментов и таким образом 8 ядер строят таблицу координат цилиндра в 8 раз быстрее И так далее А если это просто лофт из круга или куб в один сегмент? Каким макаром параллелить поток? Это вопрос не к себе, а к dassault systemes, autodesk Я думаю что в общей оценке ядро 3.5ГГц проиграет ядру 4.5, потому что далеко не все векторные операции параллелятся ядрами Кватернионы, массивы, nurms Кстати, векторные операции зашиты внутри всяких SSE Там целый пак интересных функций Кодить такое голым кодом на сях это тупо Надо подключать либы для работы с расширениями АЛУ
Karboflex
в максе? божечки кошечки
Anonim
Началось...
Karboflex
в том то и дело что кончилось)) а ты никак остановится не можешь)
Anonim
А ты в чем моделишь?